2026 Website SEO & AIO/GEO Analysis Prompts for ChatGPT, Claude, Gemini, and Grok
A model-by-model comparison of the best prompts, workflows, and interpretation rules for running SEO and GEO audits in ChatGPT, Claude, Gemini, and Grok in 2026.
The moment SEO & AIO/GEO audits met AI answer engines
Until very recently, getting a serious SEO or AIO/GEO audit meant wrangling specialized paid tools and an expert who could interpret cryptic dashboards, prioritize the noise, and translate everything into “do these five things and here’s what they’ll move.”
Today, frontier models can do a surprising amount of that early work for you—scanning your site, spotting patterns, suggesting concrete fixes, and even explaining why a particular change is likely to matter for visibility and conversions.
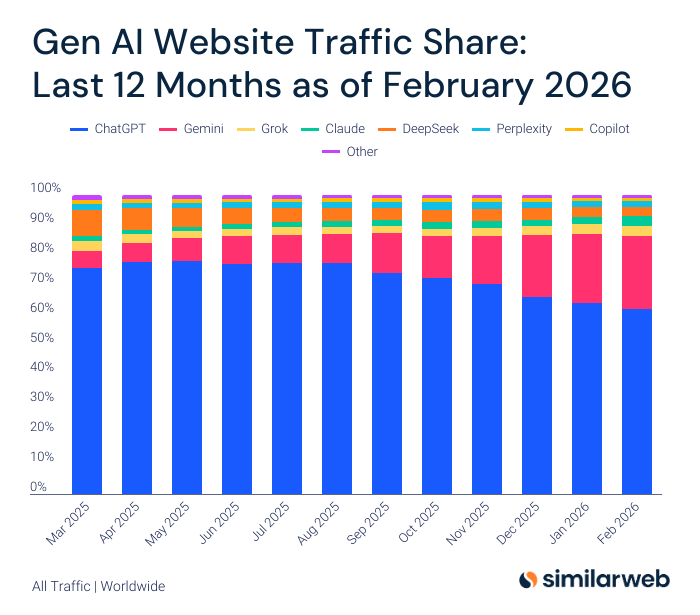
Short answer
Most teams should not pick one model and stop. ChatGPT is the broadest cross-engine benchmark, Claude is the strongest long-context strategist, Gemini is the Google-specific audit surface, and Grok is the live-language check. The best workflow is to use them together, then ship only the overlapping, high-confidence fixes first.
The market snapshot behind these prompts
| Platform | Scale signal | Interpretation for website teams |
|---|---|---|
| ChatGPT | OpenAI said ChatGPT had more than 800 million weekly users by November 5, 2025, and Similarweb still measured it as the dominant GenAI web destination. | Use ChatGPT as the broad consumer-answer benchmark and the strongest first-pass GEO stress test. |
| Gemini | Google said the Gemini app surpassed 650 million monthly users and AI Overviews reached 2 billion monthly users by November 18, 2025. | Gemini matters because Google Search is now partly a Gemini product. |
| Claude | Claude remained much smaller by web traffic, but Similarweb still measured 172.7 million visits in December 2025 after rapid growth during the year. | Claude is the specialist tool for long-context analysis, schema, and architecture. |
| Grok | Grok finished 2025 with 271.2 million web visits and 54.77 million app users, according to Similarweb and Backlinko estimates. | Grok is the best freshness and language-alignment check, especially for markets shaped by X and live conversation. |
Which model should lead your audit?
| If your main goal is... | Start with... | Why |
|---|---|---|
| Cross-engine GEO strategy | ChatGPT | It gives the broadest answer-engine simulation and the largest consumer surface. |
| Google AI Overviews and AI Mode | Gemini | It is the closest proxy for how Google will summarize and rank sources. |
| Large-site IA, schema, or docs | Claude | Claude handles long context and structure-heavy reasoning especially well. |
| Live phrasing and current-market questions | Grok | Its web and X retrieval make it strong for freshness and discourse audits. |
That doesn’t replace expert judgment, but it does change the workflow. Instead of starting with a blank spreadsheet or a generic crawler report, you can drop your URLs and ICP into ChatGPT 5.x, Claude 4.6, Gemini 3, or Grok 4.2 and get a first‑pass audit that already combines review, analysis, recommendations, and narrative explanation in one place.
This guide is written to help brands at any stage navigate that shift. It shows you how to use a SEO prompt and a AIO/GEO prompt across ChatGPT, Claude, Gemini, and Grok, tuned to what these models actually do in 2026, with clear placeholders where you can paste your own examples and results.
Why classic SEO audits are now only half the story
2026 GEO guides describe a split discovery funnel: part of the journey still looks like traditional SEO, but another part happens entirely inside AI answer engines—AI Overviews, ChatGPT answers, Gemini AI Mode, Claude/Perplexity chats, Grok’s X‑centric interface—where users might never see your blue link. Those guides converge on a few themes: answer the main question fast, structure content around conversational questions and entities, and give models clean, atomic chunks they can safely drop into an answer.
So the new audit question is: “If a 2026‑grade model reads my site today, would it understand who we’re for, when we’re the best answer, and would it choose to quote us?” The rest of this article shows you how to ask that question systematically with a pair of shared prompts you can run, side‑by‑side, in ChatGPT, Claude, Gemini, and Grok.
Before you run any prompts: your input kit
You will get dramatically better output from every model if you assemble a small input kit before you start:
- Your primary domain and any important subdomains
- A list of 10–20 priority URLs (home, pricing, 3–10 core product/feature pages, 5–10 high‑value articles or docs)
- A crisp ICP and positioning blurb (so the model can judge “good for whom?” instead of giving generic advice)
- Optional: a recent sitemap.xml or URL export, and 2–5 screenshots of mission‑critical pages (for Claude and ChatGPT vision)
For large sites, you will run the prompts on page sets, not the entire domain in one go. This aligns well with Claude Sonnet/Opus 4.6’s huge context windows and Gemini 3 and GPT‑5.4’s ability to reason over sampled URLs without wasting tokens on low‑value sections.
Part 1 – One SEO analysis prompt for ChatGPT, Claude, Gemini, and Grok
This first prompt is for classic SEO analysis with 2026‑grade reasoning: technical/structural issues, on‑page optimization, content depth, and internal linking. You can paste it directly into ChatGPT 5.3/5.4, Claude Sonnet/Opus 4.6, Gemini 3, or Grok 4.2—with a small “tool‑tuning” line added at the top.
Step 1: Prepare your inputs
To get useful, repeatable audits from any of these models, prepare a small package of inputs:
- Your primary domain and any important subdomains
- A list of priority URLs (homepage, 3–10 key product or feature pages, 5–20 top blog posts)
- A simple text description of your positioning and ICP (so the model knows what “good” looks like)
- Optional: a recent sitemap.xml, a CSV export of key URLs, or screenshots of critical pages (landing, pricing, PLG signup)
You can paste URLs directly for ChatGPT, Gemini, and Grok, and upload files or screenshots for Claude and ChatGPT. For larger sites, run page‑set audits instead of trying to audit the entire domain in a single prompt.
Step 2: SEO site‑audit prompt
**2026 SEO audit of my website**
You are a senior technical SEO and content strategist in 2026.
Your task is to run a *reasoning‑first* SEO audit of my website and turn it into a short, prioritized action plan.
**1. Context about my business**
- Brand: [BRAND NAME]
- Website: [https://www.example.com]
- ICP: [who we sell to, key segments]
- Main offer(s): [short description of products/services]
- Key markets/languages: [list]
**2. Scope**
Focus on:
- Homepage
- These 10–20 priority URLs (paste a list):
- [URL 1]
- [URL 2]
- …
- Any other URLs you discover that are clearly important (pricing, core feature pages, high‑traffic guides, docs).
**3. What you should analyze**
For the pages in scope, reason through:
1) **Technical/structural SEO (from what you can infer)**
- Internal linking depth and patterns
- Use of canonicals and obvious duplication signals
- Crawlability/indexability hints (noindex patterns, blocked sections if visible)
- Page experience signals you can infer (layout, CLS‑risk patterns, obvious performance red flags)
2) **On‑page SEO & intent alignment**
- For each key page, infer the *dominant search intent* (informational, commercial, transactional, navigational) and the main query clusters it targets
- Evaluate and improve:
- Title tag (intent clarity, scannability, entity coverage)
- Meta description (click‑worthy but not clickbait, includes key entities)
- H1/H2 structure (does it map cleanly to the user’s questions and sub‑tasks?)
- Call out keyword/entity gaps versus the intent you infer
3) **Content depth and architecture**
- Identify 5–10 core topics my site should own for my ICP and market
- For each topic, assess:
- Do we have a clear “pillar” page?
- Do we have enough supporting, interlinked content?
- Are there obvious cannibalization or duplication problems?
**4. How to think and justify**
- Do not just list generic best practices—tie every recommendation to *specific URLs, headings, or snippets of copy* you saw.
- When you say “improve X,” propose an example rewrite or structural change.
- If you are uncertain because you cannot see something (e.g., full crawl, server config), say so explicitly and suggest how a human team should verify.
**5. Outputs I want**
1) A **plain‑language executive summary** (max 250 words) of my SEO health and biggest risks/opportunities.
2) A **table** with one row per priority URL, with columns:
- URL
- Inferred primary intent
- 1–10 score for: on‑page SEO, content depth, internal linking support
- 2–3 bullet “must‑fix” items for that URL
3) A **prioritized action list** (top 15 items) across the whole site, each with:
- Impact level (high/medium/low)
- Effort level (high/medium/low)
- Why this matters *for my ICP and business model*, not just for rankings
4) 3–5 **quick wins I can ship this week** (small but high‑leverage changes).
When you are done, briefly explain *how confident you are* in your findings and where a human should validate with dedicated SEO tools.Part 2 – One AIO/GEO analysis prompt for ChatGPT, Claude, Gemini, and Grok
The second prompt focuses on AIO/GEO—how well your site is positioned to be chosen and cited by AI answer engines across tools. 2026 GEO frameworks consistently emphasize answering the main question clearly in the first 150–200 words, structuring the rest of the page around conversational question headings, and providing short, reusable answer blocks.
Step 1: model‑aware preamble
Add a one‑liner on how the model should “think like” an answer engine:
ChatGPT preamble
Think like ChatGPT GPT‑5.4 powering web answers: you choose a few high‑trust pages, then synthesize one clear answer.Claude preamble
Think like Claude 4.6 embedded inside a research assistant that must show reasoning, sources, and trade‑offs.Gemini preamble
Think like Gemini 3 powering AI Overviews and AI Mode on Google Search.Grok preamble
Think like Grok 4.2, combining live X conversations with web pages to answer what people are actually asking right now.Step 2: AIO/GEO audit prompt
**2026 AIO/GEO audit of my website**
You are a Generative Engine Optimization (GEO) strategist in 2026.
Evaluate how well my website is positioned to be **chosen and cited** by AI systems like ChatGPT, Gemini, Claude, Grok, and Perplexity when answering queries in my space.
**1. My context**
- Brand: [BRAND NAME]
- Website: [https://www.example.com]
- ICP + core use cases: [short description]
- 5–10 most important “money” queries or problems we want to own (my best guess):
- [query 1]
- [query 2]
- …
- 10–20 key URLs you should focus on (paste list).
**2. How to simulate AI answer‑engine behavior**
For each of the target queries or closely related variants:
1) Imagine you are the AI system building an answer.
- What *kinds* of pages and evidence would you want to pull from?
- Which signals would tell you “this is safe, useful, and specific enough to quote”?
2) Skim my supplied URLs (and any other obviously relevant URLs you find on my domain) and answer:
- Would you confidently use my content as a primary or secondary source? Why or why not?
- Are my intros written in a way that gives you a clear, 80–150‑word “atomic answer block” you can drop into a summary?
- Are there clear, question‑based headings and concise answer sections under them?
- Do I provide concrete examples, data, or opinions that differentiate my content from generic overviews?
Where helpful, briefly describe how **today’s leading models** (ChatGPT GPT‑5.3/5.4, Gemini 3, Claude 4.6, Grok 4.2) tend to pick and cite sources for this type of query.
**3. GEO signals to score**
For each key URL, score from 1–10 on:
- **Primary‑question clarity** – is there a clearly answered core question in the first 150–200 words?
- **Atomic answers** – does the page contain multiple short, quotable answer blocks under question‑style headings?
- **Entity & use‑case clarity** – does the content make it crystal clear *who* this is for and *what* scenarios it is best for?
- **Trust & experience** – are there visible signals of experience (case studies, examples, data, named authors, client logos, etc.)?
- **Schema / structure** – from what you can see, are there helpful structured elements (schema, tables, FAQs, comparisons) that AIs can reuse?
Present this as a table: URL, core question(s), scores on the 5 dimensions above, and 2–3 notes.
**4. Recommendations I want**
1) For each URL, propose:
- A rewritten **opening 150–200 words** that would make it an obviously strong answer source for its primary question(s).
- 3–5 **question‑based headings** to add or improve.
- 3–5 **atomic answer blocks** (80–120 words each) I should add that you, as an AI system, would love to quote.
2) At the site level, give me:
- The top 10–15 **GEO optimizations** to prioritize in the next 90 days (e.g., new topic hubs, missing comparison pages, FAQ expansions, better schema around key entities).
- A short playbook of **global content rules** my writers should follow so future pages are “answer‑engine‑ready” by default (structure, tone, evidence, length, formatting).
**5. Explain your epistemic status**
- Tell me where your analysis is based on *today’s* AI system behaviors (citing concrete patterns you’ve seen in GPT‑5.3/5.4, Gemini 3, Claude 4.6, Grok 4.2), and where you are extrapolating.
- Highlight 3–5 things my team should monitor over the next 6–12 months (changes in AI Overviews, ChatGPT linking behavior, Grok 4.2 retrieval and citation patterns, etc.).How the prompts behave differently across tools (even though they’re shared)
Even with the same prompts, the four tools don’t behave the same—and that’s useful. Modern comparisons of Sonnet 4.6 vs. Opus 4.6, GPT‑5.3 vs. 5.4, and Gemini vs. ChatGPT web answers show noticeable differences in how they route queries, allocate compute, and expose links.
Here is a quick mental model while you review outputs:
- ChatGPT (GPT‑5.3/5.4): expect strong narrative summaries, decent structural suggestions, and fewer but higher‑confidence citations; treat it as a proxy for “LLM‑centric” answer engines that prioritize self‑contained answers.
- Claude 4.6: expect very detailed reasoning, long‑form comparisons, and richer playbooks; ideal for deriving global content rules and refactoring large portions of your IA and schema.
- Gemini 3: expect advice that implicitly tracks Google’s understanding of entities and topics; use its critiques as a proxy for how AI Overviews and AI Mode see your content.
- Grok 4.2: expect more emphasis on what people are asking and saying right now on X and the web; invaluable for spotting stale content and missing angles in fast‑moving niches.
Running the same shared prompts in all four gives you a kind of model‑ensemble view of your site’s strengths and blind spots. Patterns that recur across all four tools are usually high‑leverage, while one‑off suggestions may reflect that model’s bias rather than a structural issue.
How to interpret outputs critically (and avoid low‑quality recommendations)
2025 benchmarks showed that newer “thinking” models can actually be less reliable at low‑level technical tasks (status codes, exact schema validity) than older, more constrained models and specialized tools. GEO guides also warn that AI systems are trained to be helpful and confident, which can yield over‑confident recommendations if you do not push for evidence and uncertainty.
A few guardrails:
- Treat audits as hypothesis generators, not gospel.
Use crawlers, Search Console, Lighthouse, and server logs to confirm any technical issues the models flag.
- Force models to show their work.
Ask “Which URLs and specific sections led you to this recommendation?” and “What evidence would falsify this?” instead of accepting generic advice.
- Localize every generic tip.
If a tool says “improve content quality,” follow up with “On which exact URLs, with what specific structural changes, for which primary queries?”
- Beware over‑rewrites.
In GEO experiments, focused changes—clearer openings, direct question headings, one solid comparison table—often outperform full rewrites that dilute topical authority.
- Rerun on a cadence.
GEO and AIO guidance in 2026 typically recommends quarterly audits for key pages and biannual audits for the wider library, timed to major search or model updates.
A practical multi-model workflow for 2026
- Start in ChatGPT to get an executive summary, initial GEO table, and the first prioritized action list.
- Run the same URL set in Gemini if Google is your main acquisition channel, then compare where Gemini and ChatGPT disagree about query intent or topic coverage.
- Use Claude for the pages or clusters that need architecture, schema, or long-context restructuring.
- Use Grok to refresh language, validate current questions, and see whether your headings sound current.
- Ship only overlap first by acting on the recommendations that recur across multiple models and survive validation in Search Console or crawl data.
Frequently Asked Questions
Do I still need separate SEO and GEO audits?
Yes. Classic SEO and GEO overlap, but they are not identical. SEO checks crawlability, indexation, metadata, and information architecture. GEO checks whether a page can be safely summarized, cited, and selected by answer engines.
Which model should a small team use first?
If the team can only run one audit, ChatGPT is the best default because it combines broad reach, strong reasoning, and practical output. If the business depends heavily on Google, Gemini can be the better first choice.
Why should I compare model outputs instead of trusting one?
Because each model carries a different bias. Gemini is more Google-shaped, Claude is more architecture-shaped, Grok is more freshness-shaped, and ChatGPT is more cross-engine and consumer-shaped. Overlap is usually the highest-confidence signal.
What kinds of recommendations should I validate outside the models?
Validate technical issues, indexation claims, canonical behavior, redirect chains, page-speed findings, and search-demand estimates with dedicated tools. Use the models for synthesis and prioritization, not as the final source of technical truth.
How often should teams rerun these prompts?
Quarterly is a good baseline for important pages. Teams in fast-moving categories should also rerun a lighter version after major model, AI Overview, or product-surface updates.
Continue Exploring
How to Use ChatGPT for Website SEO and AIO/GEO Analysis in 2026
Open the ChatGPT-specific workflow
How to Use Claude for Website SEO and AIO/GEO Analysis in 2026
Open the Claude-specific workflow
How to Use Gemini for Website SEO and AIO/GEO Analysis in 2026
Open the Gemini-specific workflow
How to Use Grok for Website SEO and AIO/GEO Analysis in 2026
Open the Grok-specific workflow